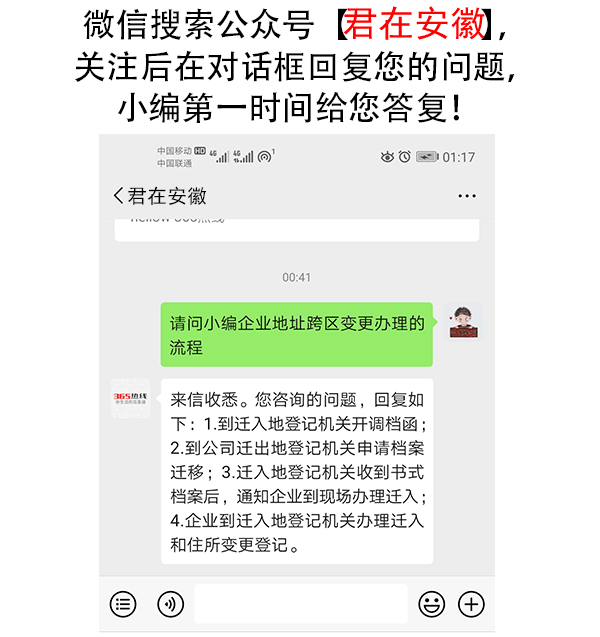
Hadoop 3.0正式登场,扩充力增加十倍,单一丛集能管10万台
历经超过一年的测试版本,终于在12月13日迎来Hadoop 3.0,而未来Hadoop社交将会加速版本更新的脚步,预计每6个月就会有一个新版本释出,而3.1与3.2版本也都在明年排定释出行程表了。Hadoop 3.0在扩充弹性下了功夫,除了改进资料保护备份的机制后,以同样实体储存容量来说,可使用容量多了50%,另外也更新了YARN功能大幅增加了扩充性。当然也装备了一些很炫的功能,像是支持Docker或是支持深度学习以及GPU加速运算技术等。
在资料备份保护的功能上,Hadoop 3.0不再使用一式三份的备份方式,而是使用纠删码,类似RAID 5或RAID 6以带状资料的方式储存,不但可以维持相同的容错能力,容量却节省了一半。
另外,Hadoop 3.0放进了新的YARN资源管理功能,不只一个丛集可以有成千上万个节点,甚至数十万个节点都没问题。YARN原本只支持一万台机器,但是在微软贡献了称为YARN Federation的功能,让Hadoop的扩充能力瞬间增加了十倍。经过的试验,一个丛集拥有四万个节点不会有太大的问题,甚至可以扩充到十万台运算节点。
值得注意的是,Hadoop生态系的扩充功能成员,不少目前都是执行JDK7,不过考量到JDK7的官方支持度已不足,在3.0以后,基于Hadoop执行的专案都要求使用JDK8,目前大资料社交正帮忙将Hadoop生态系的其他专案如HBase、Hive以及Phoenix支持FDK8。
为了跟上GPU平行运算潮流,Hadoop 3.0 YARN将能支持全型态的丛集使用CPU与GPU混合的运算,例如整合YARN与TensorFlow,终端使用者就能无缝的在深度学习或是Spark等工作中调度资源。